Capturez, identifiez et traitez vos données entrantes
OpenText | Capture Center

Le gain de productivité, la réduction des coûts opérationnels et la qualité des données sont au cœur des problématiques de l’entreprise. OpenText™ Capture Center permet l’extraction automatique et la classification des données par les technologies d’OCR (reconnaissance optique de caractères), d’ICR (reconnaissance intelligente de caractères) et d’IDR (reconnaissance intelligente de documents). Cette solution intègre de puissants moteurs de LAD/RAD (lecture automatique de documents / reconnaissance automatique de documents) et d’auto-apprentissage permettant ainsi la validation de tous types de documents professionnels structurés, semi-structurés ou libres.
Intégrée aux applicatifs métier, la solution récupère les documents entrants à partir de nombreux canaux (boites mails, scanners, fax, portails, GED, Microsoft SharePoint® et flux FTP) et permet de rapprocher les données extraites de votre référentiel afin de vous affranchir de toute intervention manuelle. Les données sont transmises au format XML pour traitement dans vos applicatifs métier, le document PDF pourra être déposé dans votre espace d’archivage.
OpenText™ Capture Center est disponible en mode on-premise, full web et dans plusieurs langues. Vos données sont sécurisées et les utilisateurs métier bénéficient d’une solution user-friendly.
Automatisez vos processus métier et maîtrisez vos données d'entreprise
Numériser
Les utilisateurs reçoivent des courriers ou des bannettes de documents à scanner de la part de leurs clients. Les documents scannés sont récupérés à partir de répertoire(s).
Importer
Les documents à traiter peuvent provenir de plusieurs sources numériques telles que des mails, portails, des flux, un système de stockage, voire une GED.
Capturer
Les documents sont récupérés et traités pour vidéocodage. Les données et documents sont transformés sous format XML et PDF.
Intégrer
Lors de l’export, les données des documents peuvent être traitées par des applicatifs métier tel qu’un ERP et des outils comptables.
Archiver
Lors de l’export, les documents traités et transformés en PDF sont archivés dans une GED avec les données du contenu pour faciliter des recherches en mode Full Text.
OpenText™ Capture Center et ses outils pour piloter l'activité

Fonction de scan en mode web
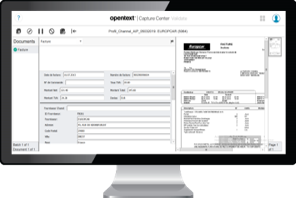
Le client de validation

Outil de monitoring
Bénéfices :
Fiabiliser et automatiser les processus métier.
Réduire les risques et coûts liés à la saisie manuelle.
Centraliser la récupération et l’enrichissement des données entrantes.
Améliorer la qualité des données et permettre une meilleure visibilité pour le métier.
Accélérer et fluidifier les processus de traitement.
Être plus compétitif en valorisant la réactivité des services auprès des clients finaux.
Cas d'usage :
Gestion des lettres d’indemnisation (Banque).
Gestion des documents d’agences immobilières avec archivage en GED (Immobilier).
Dématérialisation de 175.000 factures (Education).
BCSolutions vous accompagne !
Fort de notre expertise et de nos expériences projets, nous vous proposons de vous accompagner dans la mise en place de votre projet.
De l’analyse au déploiement, nous prendrons en charge l’ensemble des phases de votre projet.
